近日,我中心崔晓晖教授团队的李伟副教授、崔晓晖教授,以及中心合作作者张国强研究员、黎青华博士等人完成的论文,“Hierarchical Molecular Attention Network: Improving Molecular Property Prediction through Substructure Identification”,被计算生物学领域的国际老牌旗舰期刊《IEEE Transactions on Computational Biology and Bioinformatics》收录。该研究面向少样本分子属性预测中标注数据稀缺、关键子结构难以识别等问题,提出了一种层次分子注意力网络(Hierarchical Molecular Attention Network, HMAN),为药物发现、食品风味分子筛选和新材料设计等相关领域提供了新的智能预测方法。
分子属性预测是现代生物医药、食品科学和材料设计中的重要基础任务。通过预测分子是否具有特定活性或功能,研究人员可以在实验前对候选分子进行快速筛选,从而降低实验成本并提升研发效率。然而,在实际应用中,许多分子属性任务往往面临标注样本数量有限的问题。尤其是在少样本场景下,同一分子可能在不同任务中表现出不同的活性状态,传统模型若将分子中的所有原子视为同等重要,容易忽略真正决定属性的关键子结构,从而影响预测性能。
针对上述问题,研究团队提出了层次分子注意力网络HMAN。该方法从“原子-子结构-分子属性”三个层次建模分子表示。首先,模型利用图神经网络提取分子中各原子的结构特征,并通过池化操作获得分子级特征和任务相关的原型特征;随后,在原子级注意力模块中,模型结合分子特征、原型特征和原子特征,为不同原子分配任务相关权重,并筛选出高权重原子组合形成关键子结构;最后,在分子级注意力模块中,模型进一步评估不同关键子结构对分子属性预测的贡献,并选择最具代表性的子结构与分子整体特征融合,用于最终属性预测。
与已有方法相比,HMAN的核心优势在于能够显式识别与当前任务密切相关的分子关键子结构。传统少样本分子属性预测方法通常更关注分子整体表示或分子间相似性,而对分子内部不同子结构的功能贡献建模不足。HMAN通过层次化注意力机制,将任务信息引入原子组合选择过程,使模型能够根据不同属性任务动态关注不同的结构区域,从而提升模型在复杂少样本场景下的适应能力和判别能力。
此外,研究团队还设计了新的训练目标函数,将二分类交叉熵损失与加权负对数似然损失相结合。其中,交叉熵损失用于优化分子属性预测结果,加权负对数似然损失用于约束注意力权重分布,使模型分配给子结构的权重能够与其对预测结果的贡献保持一致。理论分析表明,该损失函数能够引导注意力权重分布向奖励分布收敛,从而增强模型对子结构重要性的学习能力。
该研究为少样本分子属性预测提供了一种新的层次化建模思路,不仅提升了模型在数据受限条件下的预测能力,也增强了模型对子结构贡献的可解释性。未来,该方法有望进一步拓展至食品风味分子筛选、药物活性预测、毒性评估以及功能分子设计等应用场景,为人工智能驱动的分子发现与食品科学研究提供重要方法支撑。
上述研究工作得到了 “十四五”国家重点研发计划“食品营养与安全关键技术研发”重点专项,“食品全程全息风险感知及防控体系构建与应用示范”(2022YFF1101100)的资助。
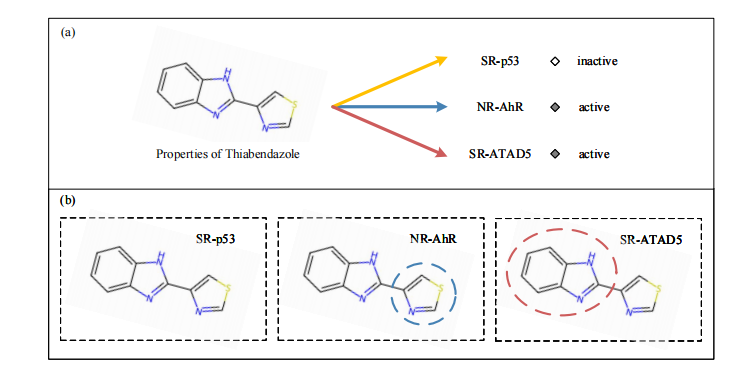
图1 分子属性预测示意图:同一分子在不同任务中可能表现出不同活性状态
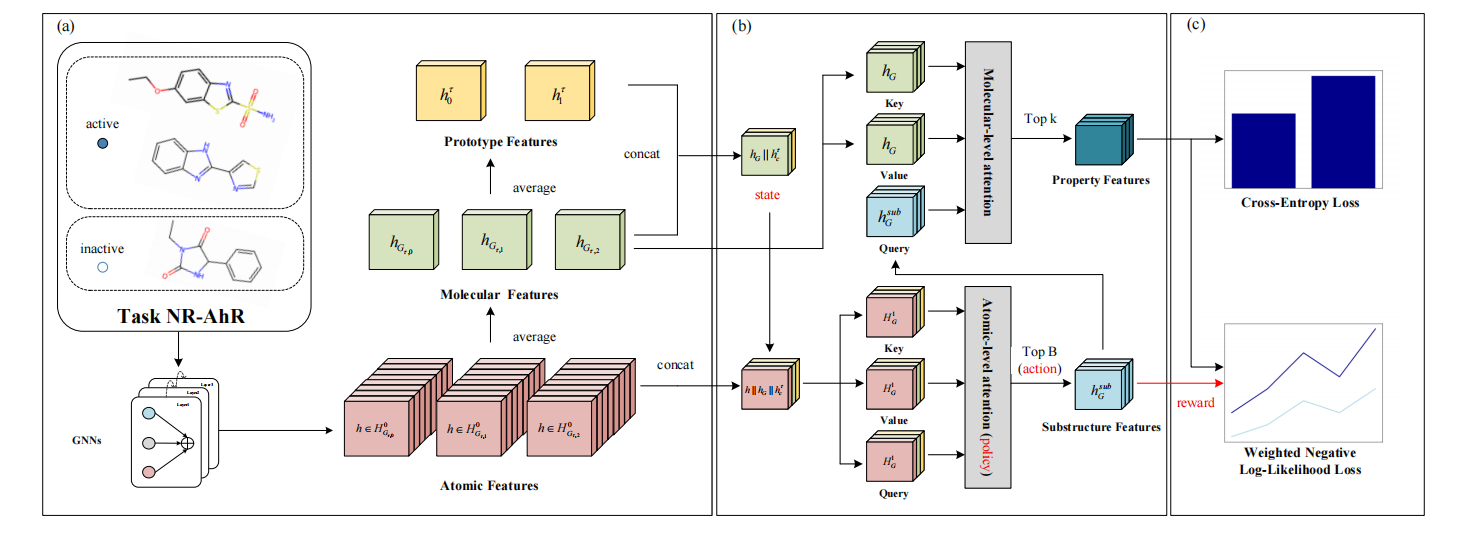
图2 HMAN模型框架:基于原子级注意力和分子级注意力识别关键子结构
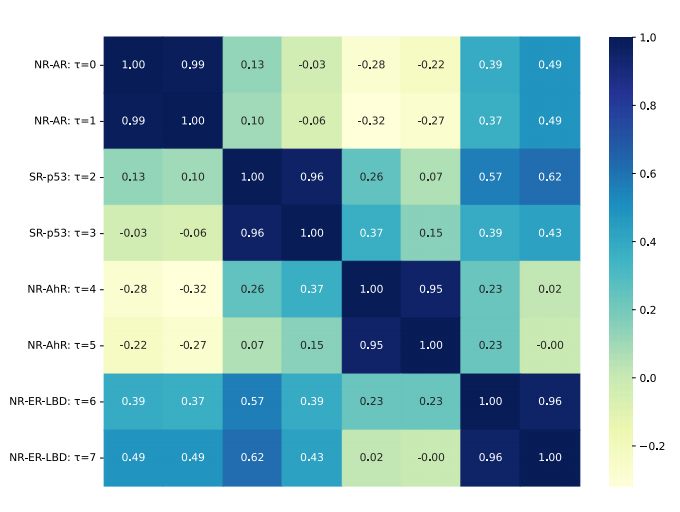
图3 原子级注意力权重相关性热力图
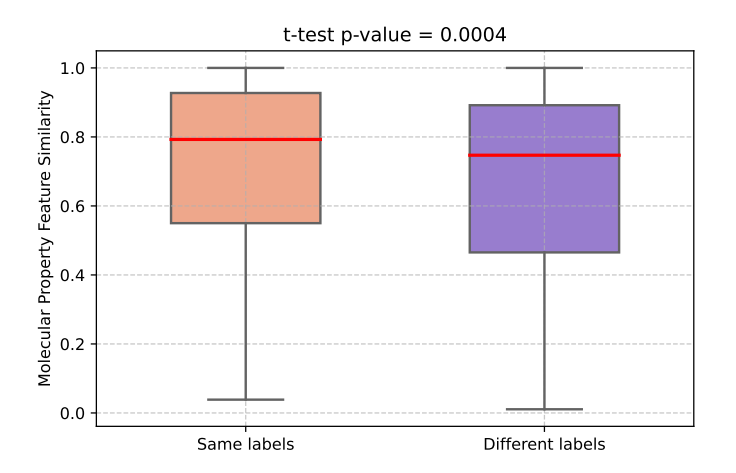
图4 分子级注意力权重相似性统计分析
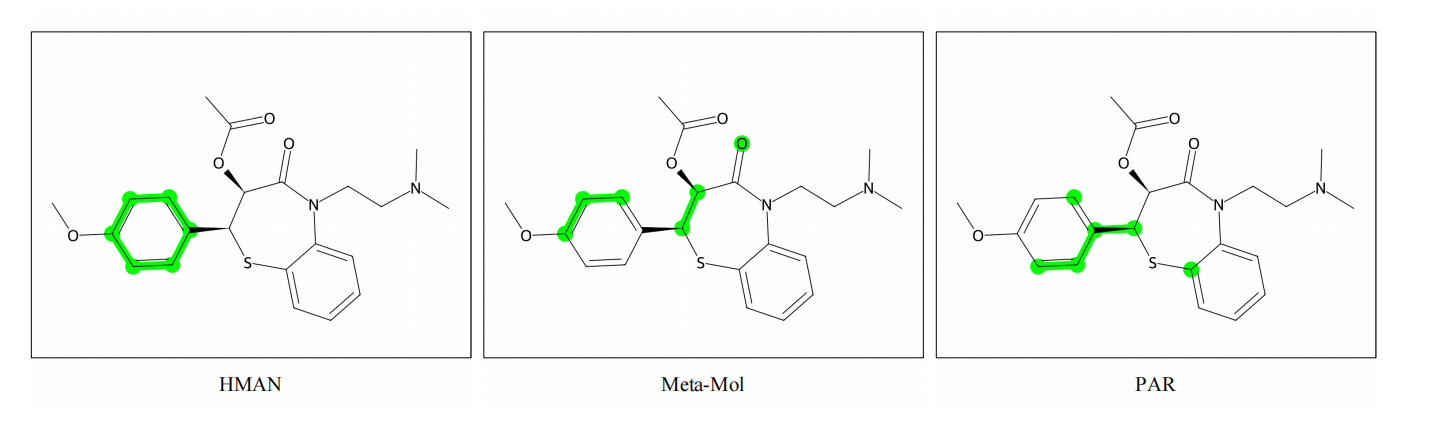
图5 BBBP任务中的关键子结构可视化
(编辑:潘梦妍)



 当前位置:
当前位置:

